
HPM Guide
XML and the Preparation of Ancient Near Eastern Texts for IT and the Internet
The Basic Concept
The common transliteration, word processors and XML
Normally a wordprocessor is used to write text editions as for other manuscripts. The advantage is, that the editor is used to its functions and does not have to bother about technical details.
The disadvantage is, that the created texts not only need the proprietary wordprocessor to be read, but also that the meaning and function of text sections is not entirely clear, although they might be marked in a was, e.g by italics. At least not to a machine.
Without the wordprocessor the text might look like above on the left (think back what was there in computers 30 years ago and imagine what will be in 30 years). This can be avoided, if one only uses characters that are defined on all computer sysems of the world and can be written with simple editors.
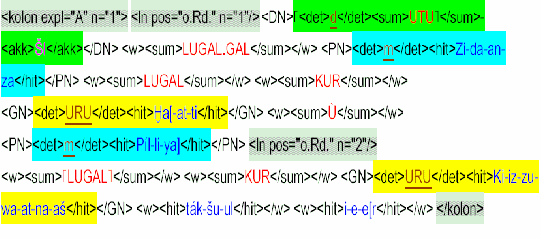
With the simple editor there would be only tabs and paragraphs to structure a text. But XML (extensible markup language), similar to the widespread HTML of billions of websites, offers a marvellous way to markup not only the look, but also the content of a text.
But would you like to type everything in XML? With Staroffice, Openoffice, Neooffice or Libreoffice, which are based on ODF (Open Document Format), it is unnecessary to do so!
An usual transliteration contains numerous mark-ups, which are usually used ambigiously. Even headings are mostly formated by clicking the fat and the underline buttons and increasing the size of the characters, although all this could be achieved by a simple click on the Heading style.
In the example above superscript, small caps and italics are used to distinguish line no., logogram and Hittite text. But in other passages the meaning of these formats might be quite different.
Thus it is better to use named styles that do not only show certain characteristics but tell by there names something about their content. These named styles can be processed automatically as the Headings can be used to generate the table of contents automatically.
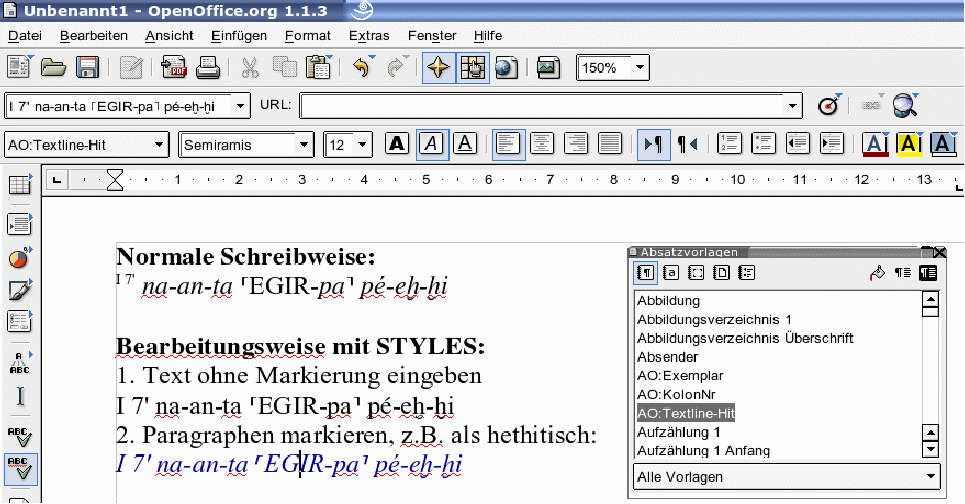
The easiest way is to start with typing the pure characters without any style information (or clean text from old files by applying „Format → Standardformat“).
Then apply the named style which tells us about the basic function or meaning of the paragraph (in the above example it is a Hittite text marked by the paragraph style ¶ „AO:Textline-Hit“ .
The colors are used for clarity only!
Tables, Paragraphs and Character Styles

Below the paragraph level character styles a are used to mark those elements that are not yet sufficiently defined by the mark-up of the paragraph/textline itself. E.g. the Hittite textline is marked as Hittite as a whole, only Sumerogram and line no. have to be marked separately, NOT every single word.
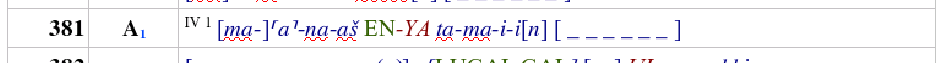
Above the paragraph level table rows connect informations of the singel cells automatically (here the Hittite textline/paragraph with the exemplar and line no.).
The editor does not have to care about XML. The ODT files of the mentioned word processors are zipped xml files.

We recommend the above mentioned wordprocessors Staroffice, OpenOffice, NeoOffice und LibreOffice. Of course you can use other programs as long as their files can be imported into the forementioned.
This kind of text mark-up can easily be
applied to other projects, where old manuscripts have to be
prepared for an electronic reuse, since the mark-up is done
quickly with the Fill Format Mode
![]() like with a text marker.
like with a text marker.
Synoptic Text Editions
Three independent files are used for the internet presentation of synoptic texts (cf sample files):
- Introduction ( ..._in.odt)
- Transliteration ( ..._tx.odt)
- Translation (..._ DE-tr.odt, ..._IT-tr.odt etc.)
Each textgroup contains its own bibliography and table of content.
The Introduction
The example file „Vorlage-Intro“ contains the necessary formats and is almost self explaining.
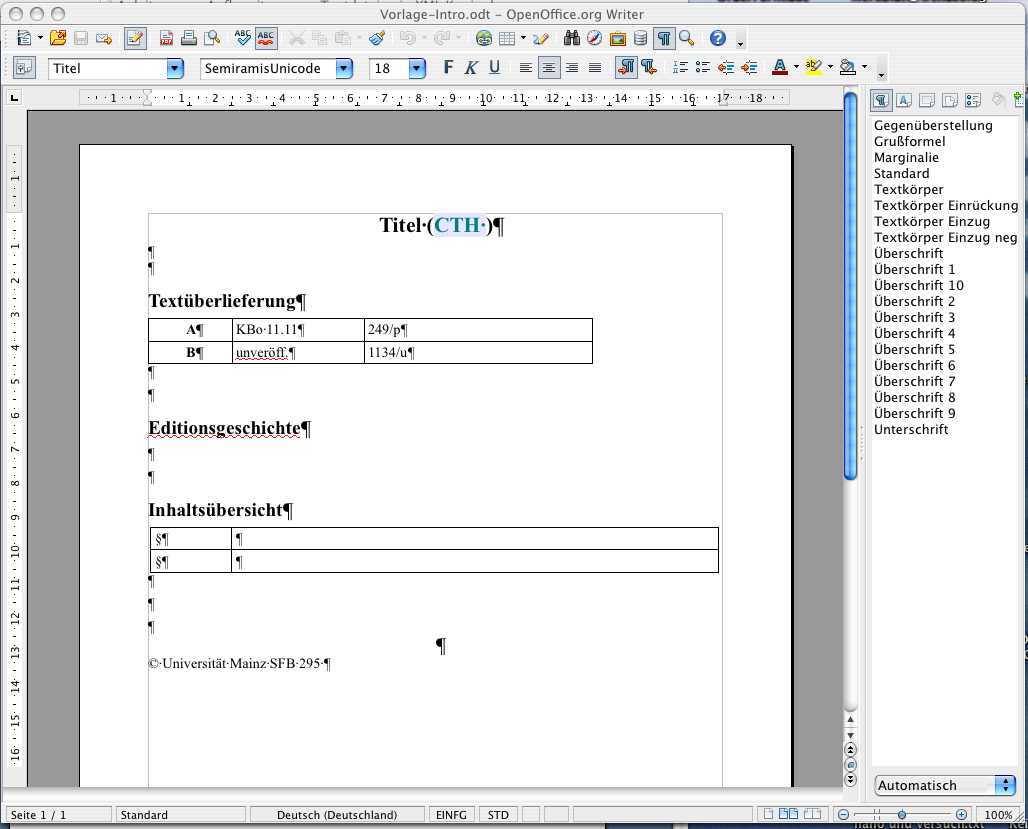
First to be filled:
- Title
- CTH no. (resp. the textno. under which all exemplars of a composition are registered).
The second section gives the fragments that belong to each exemplar.
The third sections reports the history of the reception and reconstruction of the texts as well as the editors.
This section can be followed by an overview of the content as text or in tabulary form.
Finally the introductory file has to be saved as „CTH nnn_in“, e.g. CTH 234.II.4_in.
The parts of a text exemplar may be differenciated by indices, e.g. A2..
The Transliteration
The file „Vorlage-Translit“ comprises the styles.
We recommend to let the cursor rove the text in order to study the usage of the paragraph and character styles.
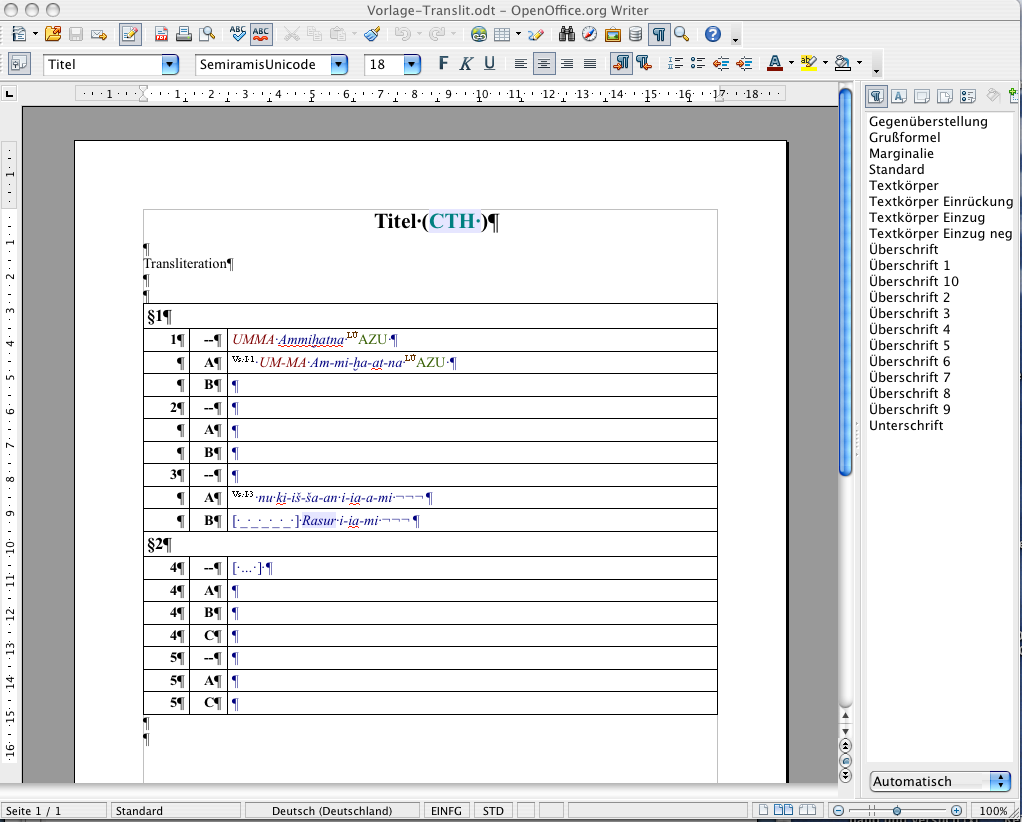
The table can be expanded by insertion of rows (Table → Insert → Rows) or by proceding with TAB.
Here the selected paragraph style is Hittite text. The non-Hittite passages only have to be marked up.
The Hittite text automatically appears as italics and the text is inambiguously identified as Hittite. One must NOT mark each Hittite word with the character style AO:Hittite, which is only applied in context, where the paragraph itself is not marked as Hittite!
Only determinatives, line nos., logograms etc. have to be marked up.
Passages of a text in another language are marked with the appropriate language style for paragraphs, e.g. Hurrian in a Hittite ritual, if these passages are clearly separate. The character style AO:Hurrian however, is only used for short inserted or incomplete citations of Hurrian spells or single words.
|
AO:--index |
Markierung von Index-Ziffern NA₄ |
|
AO:--superscr |
Markierung von Hochstellungen -ta!- |
|
AO:-LineNrExpl |
Markierung der Zeilenangaben |
|
AO:-LIT |
Markierung der Literaturangaben (Name Jahr), z.B. Groddek 2009 |
|
AO:-Text-Gap |
Markierung zusätzlicher Informationen wie z.B. Rasur |
|
AO:Akkadian |
Markierung akkadischer Textabschnitte oder Wörter |
|
AO:AkkGRAM |
Markierung von Akkadogrammen |
|
AO:Determ. |
Markierung von Determinativen |
|
AO:DocSigl |
Markierung der Textnummer in den Dokumenten-Überschriften, bei hethitischen Texten die CTH-Nr. |
|
AO:editor |
Markierung des Bearbeiters im Inhaltsverzeichnis |
|
AO:Hattian |
Markierung hattischer Wörter in Transliteration und Übersetzung |
|
AO:Hittite |
Markierung hethitischer Wörter in Übersetzungen |
|
AO:Hurrian |
Markierung hurritischer Wörter in Transliteration und Übersetzung |
|
AO:InvNr |
Markierung der Textinventarnr. auf der Introseite sowie in Fußnoten (nur z.B. Bo 2030, nicht „+“, „(+)“ o.ä.) |
|
AO:Luwian |
Markierung luwischer Wörter in Transliteration und Übersetzung |
|
AO:Numeral. |
Markierung von Zahlen |
|
AO:Sumerian |
Markierung sumerischer Textabschnitte oder Wörter |
|
AO:SumGRAM |
Markierung von Sumerogrammen |
|
AO:TxtPubl |
Markierung der Textpublikation auf der Introseite sowie in Fußnoten (nur z.B. KUB 29.1, nicht „+“, „(+)“ o.ä.) |
|
AO:CTH-Link |
Markierung von CTH-Nr. in Fußnoten |
Please note:
When copying text from elder files (e.g. Word) it might be necessary to save them as Unicode texts first.
Lacunae: If the number of signs broken can be guessed, „_“ or „_ (_)“ should be used. Lacunae of unknown size are marked by „ ...“, in the Master text only „[…]“. is used.
The paragraphs are set according to the paragraph lines in the „main“ text
Paragraph lines are marked in each exemplar (¬¬¬ or === für double lines), but not in the master text.
We use /y/ und /w/ instead of other characters common in ANE philology. Vowels are harmonized (no „_i-e_“ without morphological reasons).
The coding of Hurrian
analytic transliteration according to common criteria (cf. e.g. I. Wegner, Einführung, 2000, 39ff. und G. Wilhelm, Hurrian, in: Woodard, R. D. (ed.), The Cambridge Encylopedia of the World’s Ancient Languages, 2004, 98f.)
vereinfachte gebundene Umschrift
- Unterscheidung von stimmhaften und stimmlosen Konsonanten (somit auch von Einfach- und Doppelkonsonanz) (auch Verwendung der Zeichen ġ und ž)
stimmhaft: wenn Konsonant intervokalisch (a-ta-ni zu adani); im Wortauslaut; in Kontaktstellung mit l, m, n, r (ar-te zu arde)
stimmlos: am Wortanfang (da-ḫe zu taġe); in Kontaktstellung mit anderen Konsonanten ≠ l, m, n, r; doppelter Konsonant (ad-da-ni zu attani)
- Unterscheidung von /e/ und /i/ (diese – wie auch die folgenden Unterscheidungen – ist wichtig, um verschiedene Wörter und Morpheme zu trennen)
- Unterscheidung von /u/ und /o/
- Unterscheidung von /p/ bzw. /b/ und /f/ bzw. /v/ bzw. /w/
- !aber!:
Angabe der Pleneschreibung durch ā, ē, ī, ō, ū (in Zukunft vielleicht nützlich, um Wörter zu unterscheiden (vgl. z.B. ḫa-aš- und ḫa-a-aš-))
keine Verwendung von j
Die Umschrift der Wörter sollte dem entsprechen, was man in der aktuellen Literatur (z.B. Glossare) findet. Sollten verschiedene Wiedergaben eines Wortes (z.B. ob /p/ oder /f/ geschrieben werden sollte) existieren, könnte man p/f… schreiben.
Zweite Zeile:
- keine Unterscheidung von Einfach- und Doppelkonsonanz
- nur stimmlose Konsonanten
- keine Unterscheidung von /e/ und /i/ (nur /i/ wird verwendet)
- keine Unterscheidung von /u/ und /o/ (nur /u/ wird verwendet)
- nur /p/ (also kein /f/)
- keine Angabe der Pleneschreibung
- Bevorzugung der jeweils niedrigsten Silbenwerte
Das so erstellte Dokument sollte in der Form „CTH nnn_tx“ abgespeichert werden.
Die Übersetzung
Für die Übersetzung ist das Dokument „Vorlage-Translat“ aufzurufen, in dem die Formatvorlagen bereits in der erforderlichen Weise vorbereitet sind.
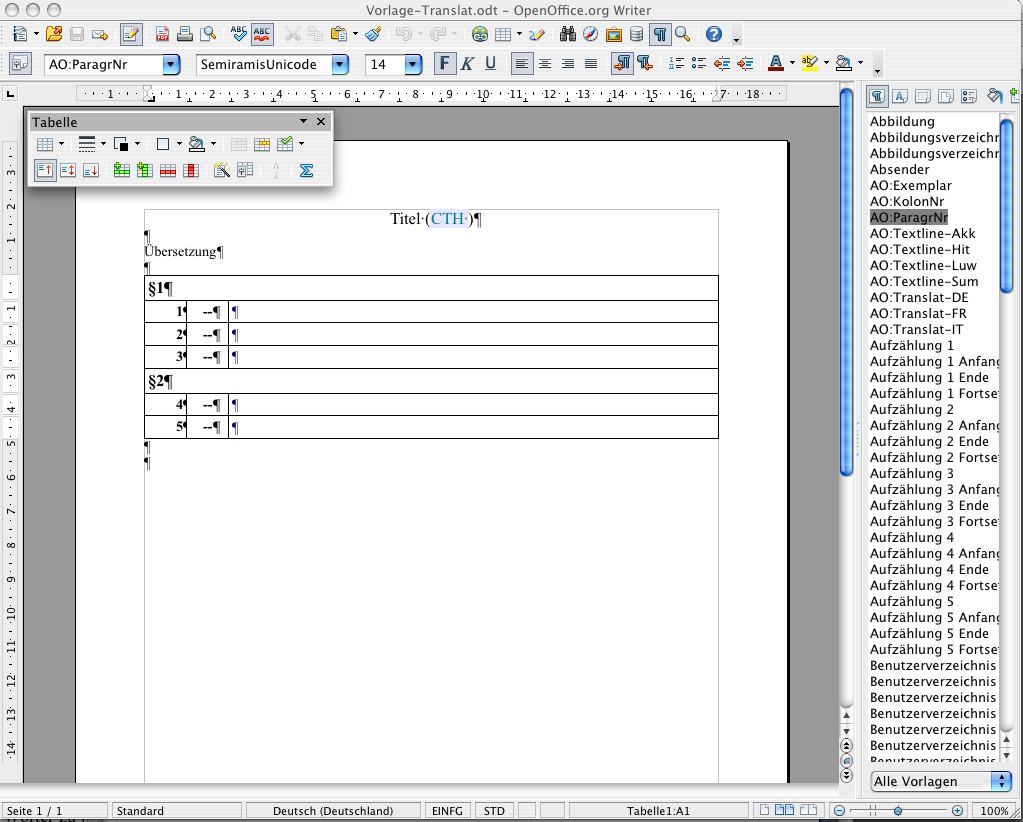
Auch hier sind Titel und CTH-Nr. des bearbeiteten Rituals einzutragen; für die rechte Spalte ist die Formatvorlage entsprechend der Sprache der Übersetzung auszuwählen (bislang Deutsch, Englisch, Französisch, Italienisch).
Das Dokument ist in der Form „CTH nnn_DE-tr“ oder „CTH nnn_EN-tr“ bzw. „CTH nnn_FR-tr“ bzw. „CTH nnn_IT-tr“ abzuspeichern.
Redaktion Susanne Görke, Gerfrid G.W. Müller