Elisabeth Rieken
Citatio: E. Rieken, hethiter.net/: HFR-Annotation (2021-12-31)
Principles of the Lexical and Morphological Annotation in HFR
The texts of the basic corpus are lexically and morphologically annotated. The aim of the annotation is essentially an indexing of the linguistic form of the texts, which in the Hittite writing culture can differ considerably from the appearance of the text due to the function and use of the cuneiform script.

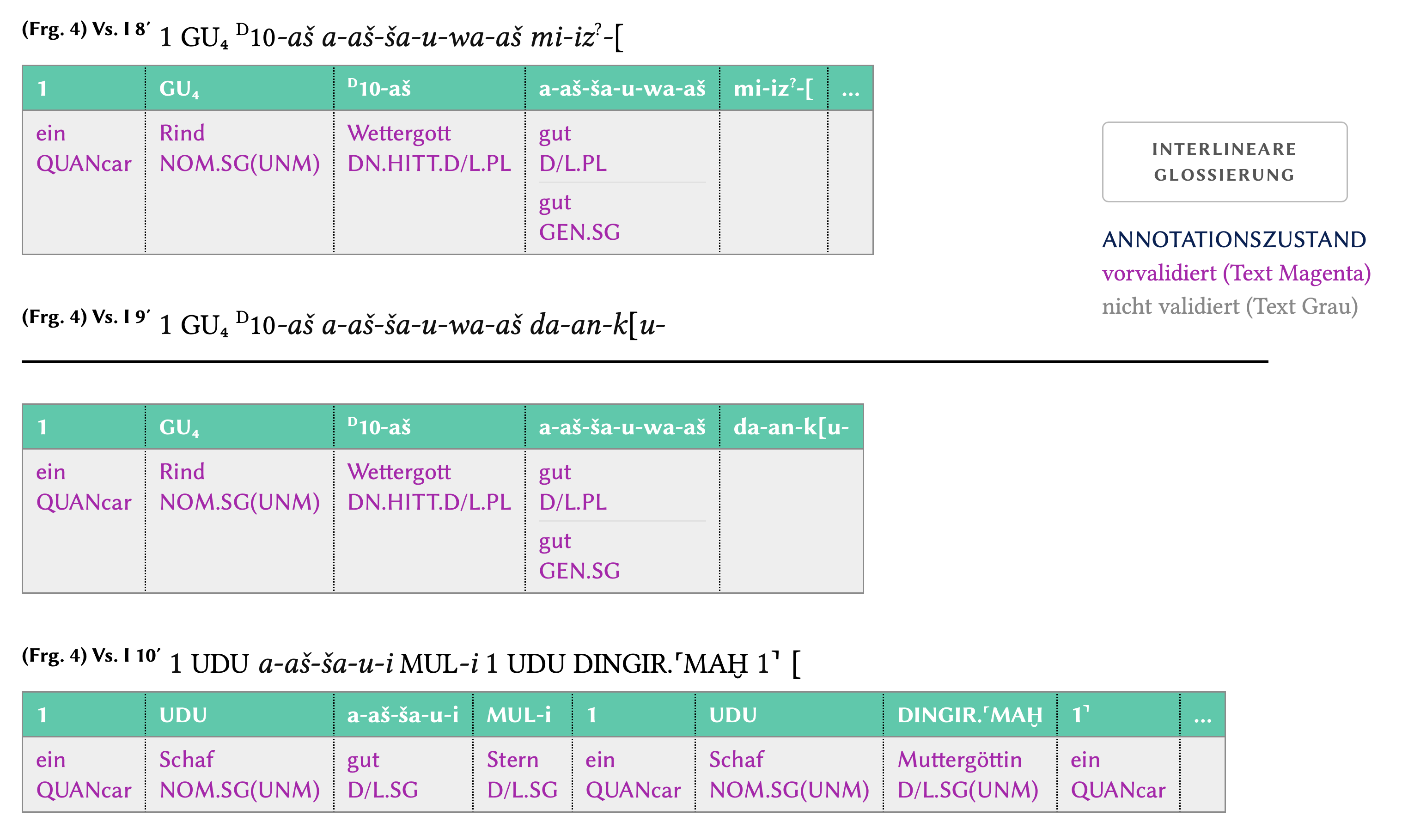
View of a text in the basic corpus, displaying the lexical and
morphological analysis (in magenta via mouseover function)
of the relevant word (marked by gray background).
The lexical and morphological annotation is carried out in a three-step process of automatic annotation and manual validation.
(1) In the first step (automatic annotation), the attested word forms are compared with a list of all potential word forms of the entire Hittite lexicon and linked to the hits. The resulting automatically generated annotation is based exclusively on a morphological analysis of the recognized lexemes – without taking the context into account. In the case of ambiguous forms, there are multiple suggestions. This automated annotation is already offered for all texts of the basic corpus. In the mouseover and in the interlinear view, it is shown in grey.
(2) In the second step (manual prevalidation), the multiple suggestions of the automatic annotation within the basic corpus are reduced as far as possible by project members, taking into account the syntax and the meaning of the text. Beyond the clear lexical and morphological analyses, cases of ambiguity still remain, especially in fragmentary contexts. The prevalidation process is already complete for many of the most important manuscripts of the festival texts. In the mouseover and in the interlinear view, it is shown in magenta.
Interlinear view of a text in the basic corpus: the upper line (green) contains the transliteration
of the cuneiform text, below it stands the meaning with morphological glossing (magenta).
(3) The third and final step of annotation occurs through the manual validation within the production of the critical editions of selected festival texts. This final process of validation is based upon an understanding of the text that can only be attained through the process of reconstructing, translating and commenting upon the texts.
Further information on the annotation principles is presented below under 1–8 according to individual topics and problems. Detailed documentation of the annotation can be found in the internen Handreichungen. A list of abbreviations of the morphological glossing can be viewed in HTML (in a separate window) or downloaded as a PDF.
- Generalities
- Handling of foreign-language material
- Default decisions for ambiguous case forms, local particles and logograms
- Contents and measures
- Number agreement after cardinal numbers
- Cases in lists
- Graphical brackets by Akkadian case classifiers
- Sumerographic adpositions
1. Generalities
- In principle, the paradigm slot is indicated, not the form; i.e., the (syntactic) understanding of the text is taken into account in the annotation and systematic morphological ambiguity (e.g., in the nominative/accusative of the neuter) is eliminated whenever the context permits.
- In the case of ambiguous morphological analysis, all possibilities are indicated. In a fragmentary context, a word is annotated unambiguously, only when the form can be analyzed with certainty on the basis of the context or the text genre. Otherwise, all possibilities are indicated.
- For forms ambiguous with regard to their inflectional class, only one of the possibilities, namely the normal inflection class, is indicated.
- If in the text an irregular form occurs that is neither to be included in the paradigm nor to be changed in the basic corpus, the correct morphological analysis is marked with an exclamation mark in parentheses in the course of the manual validation process.
2. Handling of foreign language material
- Cohesive Hurrian and Hattic text passages are not morphologically annotated. They are only automatically referred to as ‘HUR’ or ‘HAT’
- When embedded in Hittite context, Hurrian and Hattic word forms are annotated lexically and morphologically as far as possible.
- Palaic text passages are already annotated.
- The annotation of Luwian text passages is planned for the near future.
3. Default decisions for ambiguous case forms, local particles and logograms
- When an object is requested in a ritual context, the noun in question is annotated as a nominative (e.g., “The zither (scil. shall be brought)!”).
- Despite the post-Old Hittite case syncretism of the ablative and instrumental, all instances in which both cases come into question because they are not formally distinguished are annotated as both ablative and instrumental, since the New Hittite writers may also have copied Old Hittite instrumental forms (e.g., NH IŠ-TU BI-IB-RI with the annotation as INS and ABL).
- Local particles such as anda, which can be interpreted as adverbs, preverbs or postpositions, are annotated as adverbs (ADV) in absolute or elliptical use.
- For logograms, the singular is the default number. Logograms are annotated as plural forms, only if they are marked by a plural determinative. After cardinal numbers, however, the rules listed under 5 apply.
4. Contents and measurements
- The genitive is the default case for uncomplemented logograms for the material or content of an object, whereas the appositional construction (‘ein Korb Äpfel’) is not applied:
- DUGtapišaniš KÙ.SI₂₂ (GEN.SG) ‘a t.-vessel of gold’,
- DUGtaḫašiuš=ma GEŠTIN (GEN.SG) ‘a t.-vessel of wine’,
- but clearly marked: DUGḫuppar GEŠTIN-it (INS) ‘a bowl with wine’.
- The same applies to TA-PAL ‘a pair’ (+ GEN).
- The annotation is handled differently for measurements, weights, units of value and memal- ‘groats’. The case of the measured object and the case of the units of measurement are congruent; thus, they form an apposition:
- 4 (QUAN) GÍN (NOM.SG) KÙ.SI₂₂ (NOM.SG) ‘four shekels of gold’
- Postposed units of weight or measures of capacity are analyzed as genitives (tarnaš and UP-NI ‘of a handful’).
- 4 (QUAN) NINDAḫaršauš (NOM.PL) tarnaš (GEN.SG) ‘four ḫ.-Breads of a handful’
5. Number agreement after cardinal numbers
The annotation of unmarked nominal expressions is based on the following rules. After cardinal numbers ≥ 2 follow
- semantically animate common gender nouns in the plural (gods, humans, animals, also human body parts) as well as semantically inanimate common gender nouns after the cardinal numbers 2–4;
- Exception 1: Collectives (such as soldiers, fallen, hostages, travelers, herd animals and birds) are annotated as singular forms, e.g.: 80 MUŠENḪI.A (SG) ḫu-el-pí-iš ‘80 young birds’.
- Exception 2: In lists (especially, of offerings and paraphernalia) the listed items are often in the singular except semantically animate common gender nouns, even if the cardinal number is 2, 3 or 4.
- in the singular (even if a plural determinative is present) Neutra as well as semantically inanimate common gender nouns after cardinal numbers ≥ 5;
- Exception: If objects are separated or distributed in the following context, the nominal expressions are annotated as distributive plural forms.
- NB: Unclear instances (for instance, if the Hittite equivalent of a logogram is unknown) are annotated with both numbers (SG and PL), by default.
- NB: In the absence of plural determinatives, the above rules for number agreement after cardinal numbers apply, independent of the uses of plural classifiers.
6. Cases in lists
In lists (especially of offerings and ritual equipment), there is a distinction between
- “syntactically independent lists” (introduced by kiššan, QATAMMA, etc., and not followed by a sentence-final verb form):
- The listed items are typically in the nominative. Here, the items are annotated as NOM. If an accusative form nevertheless occurs in an otherwise “syntactically independent list”, this is annotated as an intended nominative with the addition of (!), e.g., NOM. SG.C(!);
- “lists within sentences” (with a verbal form such as da(nz)i, pai, piyanzi, išpanti etc. at the end of the list):
- The items of the list function syntactically as direct objects of the verbal form and are typically in the accusative. Here, the elements are annotated as accusative. If a nominative form nevertheless occurs in a “list within a sentence”, this is annotated as an intended accusative with the addition of (!), e.g., ACC. SG.C(!).
- In unclear instances, for example in a fragmentary context, the nominative is used as the default case. However, if a single accusative form occurs and otherwise no other caseform can be identified (e.g., since otherwise only logograms are present), the forms are annotated as accusatives, and the case can be generalized from this form to the entire list.
- If stem forms are used as pseudo-logograms, i.e. if the words show no endings, they are annotated as the expected case form, with the addition of “(UNM)”. The default number is the singular, if there are no contradictory indications, e.g.:
- 3 (QUAN) PA (NOM.SG) ZÌ.DA (NOM.SG) še-ep-pí-it (GEN.SG(UNM)(!)) ar-ra-an-ta-aš (GEN.SG)
- 5 (QUAN) DUGpal-ḫi (NOM.SG(UNM)) GAL (NOM.SG(UNM)) – N.B.: palḫi ist kein Neutrum!
- 3 (QUAN) PA-RI-SI še-ep-pí-it-ta-aš (GEN.SG) ar-ra-an-za (GEN.SG(UNM)(!))
7. Graphical brackets written by Akkadian case classifiers
- In IŠ-TU MUNUS.LUGAL GIŠBANŠUR ‘from the Queen’s table’ the case classifier IŠ-TU does not mark the immediately following logogram MUNUS.LUGAL ‘Queen’, but the entire noun phrase headed by GIŠBANŠUR ‘table’. To mark this, the case classifier is also annotated (CLFcas-np).
8. Sumerographische Adpositionen
- The Sumerographic adpositions EGIR, ŠÀ and TA are combined for annotation to form a single unit with the noun governed by them (connected by underscore), e.g.:
- EGIR GIŠBANŠUR ‘behind the table’ (table:D/L_hinter:POSP).

The Corpus of Hittite Festival Rituals | E. Rieken, 2021
Hethitologie-Portal Mainz | G.G.W. Müller 2002–2026, Ch.W. Steitler 2021–2026

This work is licensed under a Creative Commons Attribution-ShareAlike 4.0 International License.
www.hethiter.net